 Nageru 1.4.0
Nageru 1.4.0 is out (and on its way through
the Debian upload process right now), so now you can do live video mixing with multichannel
audio to your heart's content. I've already blogged about most of the
interesting new features, so instead, I'm trying to answer a question:
What took so long?
To be clear, I'm not saying 1.4.0 took more time than I really anticipated
(on the contrary, I pretty much understood the scope from the beginning,
and there was a reason why I didn't go for building this stuff into 1.0.0);
but if you just look at the changelog from the outside, it's not immediately
obvious why multichannel audio support should take the better part of three
months of develoment. What I'm going to say is of course going to be obvious
to most software developers, but not everyone is one, and perhaps my
experiences will be illuminating.
Let's first look at some obvious things that
isn't the case: First of all,
development is not primarily limited by typing speed. There are about 9,000
lines of new code in 1.4.0 (depending a bit on how you count), and if it was
just about typing them in, I would be done in a day or two. On a good
keyboard, I can type plain text at more than 800 characters per minute but
you hardly ever write code for even a single minute at that speed. Just as
when writing a novel, most time is spent thinking, not typing.
I also didn't spend a lot of time backtracking; most code I wrote actually
ended up in the finished product as opposed to being thrown away. (I'm not
as lucky in all of my projects.) It's pretty
common to do so if you're in an exploratory phase, but in this case, I had a
pretty good idea of what I wanted to do right from the start, and that plan
seemed to work. This wasn't a
difficult project per se; it just needed
to be
done (which, in a sense, just increases the mystery).
However, even if this isn't at the forefront of science in any way (most code
in the world is pretty pedestrian, after all), there's still a lot of
decisions to make, on several levels of abstraction. And a lot of those
decisions depend on information gathering beforehand. Let's take a look at
an example from late in the development cycle, namely support for using MIDI
controllers instead of the mouse to control the various widgets.
I've kept a pretty meticulous TODO list; it's just a text file on my laptop,
but it serves the purpose of a ghetto bugtracker. For 1.4.0, it contains 83
work items (a single-digit number is not ticked off, mostly because I decided
not to do those things), which corresponds roughly 1:2 to the number of
commits. So let's have a look at what the ~20 MIDI controller items went into.
First of all, to allow MIDI controllers to influence the UI, we need a way
of getting to it. Since Nageru is single-platform on Linux, ALSA is the
obvious choice (if not, I'd probably have to look for a library to put
in-between), but seemingly, ALSA has two interfaces (raw MIDI and sequencer).
Which one do you want? It sounds like raw MIDI is what we want, but actually,
it's the sequencer interface (it does more of the MIDI parsing for you,
and generally is friendlier).
The first question is where to start picking events from. I went the simplest
path and just said I wanted all events anything else would necessitate a UI,
a command-line flag, figuring out if we wanted to distinguish between
different devices with the same name (and not all devices potentially even
have names), and so on. But how do you enumerate devices? (Relatively simple,
thankfully.) What do you do if the user inserts a new one while Nageru is
running? (Turns out there's a special device you can subscribe to that will
tell you about new devices.) What if you get an error on subscription?
(Just print a warning and ignore it; it's legitimate not to have access to
all devices on the system. By the way, for PCM devices, all of these answers
are different.)
So now we have a sequencer device, how do we get events from it? Can we do it in the main loop? Turns out
it probably doesn't integrate too well with Qt, but it's easy enough to put
it in a thread. The class dealing with the MIDI handling now needs locking;
what mutex granularity do we want? (Experience will tell you that you nearly
always just want one mutex. Two mutexes give you all sorts of headaches with
ordering them, and nearly never gives any gain.) ALSA expects us to poll()
a given set of descriptors for data, but on shutdown, how do you break out
of that poll to tell the thread to go away? (The simplest way on Linux is
using an eventfd.)
There's a quirk where if you get two or more MIDI messages right after each
other and only read one, poll() won't trigger to alert you there are more
left. Did you know that? (I didn't. I also can't find it documented. Perhaps
it's a bug?) It took me some looking into sample code to find it. Oh, and
ALSA uses POSIX error codes to signal errors (like nothing more is
available ), but it doesn't use errno.
OK, so you have events (like controller 3 was set to value 47 ); what do you do
about them? The meaning of the controller numbers is different from
device to device, and there's no open format for describing them. So I had to
make a format describing the mapping; I used protobuf (I have lots of
experience with it) to make a simple text-based format, but it's obviously
a nightmare to set up 50+ controllers by hand in a text file, so I had to
make an UI for this. My initial thought was making a grid of spinners
(similar to how the input mapping dialog already worked), but then I realized
that there isn't an easy way to make headlines in Qt's grid. (You can
substitute a label widget for a single cell, but not for an entire row.
Who knew?) So after some searching, I found out that it would be better
to have a tree view (Qt Creator does this), and then you can treat that
more-or-less as a table for the rows that should be editable.
Of course, guessing controller numbers is impossible even in an editor,
so I wanted it to respond to MIDI events. This means the editor needs
to take over the role as MIDI receiver from the main UI. How you do
that in a thread-safe way? (Reuse the existing mutex; you don't generally
want to use atomics for complicated things.) Thinking about it, shouldn't the
MIDI mapper just support multiple receivers at a time? (Doubtful; you don't
want your random controller fiddling during setup to actually influence
the audio on a running stream. And would you use the old or the new mapping?)
And do you really need to set up every single controller for each bus,
given that the mapping is pretty much guaranteed to be similar for them?
Making a guess bus button doesn't seem too difficult, where if you
have
one correctly set up controller on the bus, it can guess from
a neighboring bus (assuming a static offset). But what if there's
conflicting information? OK; then you should disable the button.
So now the enable/disable status of that button depends on which cell
in your grid has the focus; how do you get at those events? (Install an event
filter, or subclass the spinner.) And so on, and so on, and so on.
You could argue that most of these questions go away with experience;
if you're an expert in a given API, you can answer most of these questions
in a minute or two even if you haven't heard the exact question before.
But you can't expect even experienced developers to be an expert in all
possible libraries; if you know everything there is to know about Qt,
ALSA, x264, ffmpeg, OpenGL, VA-API, libusb, microhttpd
and Lua
(in addition to C++11, of course), I'm sure you'd be a great fit for
Nageru, but I'd wager that pretty few developers fit that bill.
I've written C++ for almost 20 years now (almost ten of them professionally),
and that experience certainly
helps boosting productivity, but I can't
say I expect a 10x reduction in my own development time at any point.
You could also argue, of course, that spending so much time on the editor
is wasted, since most users will only ever see it once. But here's the
point; it's not actually a lot of time. The only reason why it seems
like so much is that I bothered to write two paragraphs about it;
it's not a particular pain point, it just adds to the total. Also,
the first impression matters a lot if the user can't get the editor
to work, they also can't get the MIDI controller to work, and is likely
to just go do something else.
A common misconception is that just switching languages or using libraries
will help you a lot. (Witness the never-ending stream of software that
advertises written in Foo or uses Bar
as if it were a feature.)
For the former, note that nothing I've said so far is specific to my choice
of language (C++), and I've certainly avoided a bunch of battles by making
that specific choice over, say, Python. For the latter, note that most of these problems are actually related
to library use libraries are great, and they solve a bunch of problems
I'm really glad I didn't have to worry about (how should each button look?),
but they still give their own interaction problems. And even when you're a
master of your chosen programming environment, things
still take time,
because you have all those decisions to make on
top of your libraries.
Of course, there are cases where libraries really solve your
entire problem
and your code gets reduced to 100 trivial lines, but that's really only when
you're solving a problem that's been solved a million times before. Congrats
on making that blog in Rails; I'm sure you're advancing the world. (To make
things worse, usually this breaks down when you want to stray ever so
slightly from what was intended by the library or framework author. What
seems like a perfect match can suddenly become a development trap where you
spend more of your time trying to become an expert in working around the
given library than actually doing any development.)
The entire thing reminds me of the famous essay
No Silver Bullet by Fred
Brooks, but perhaps even more so, this quote from
John Carmack's .plan has
struck with me (incidentally about mobile game development in 2006,
but the basic story still rings true):
To some degree this is already the case on high end BREW phones today. I have
a pretty clear idea what a maxed out software renderer would look like for
that class of phones, and it wouldn't be the PlayStation-esq 3D graphics that
seems to be the standard direction. When I was doing the graphics engine
upgrades for BREW, I started along those lines, but after putting in a couple
days at it I realized that I just couldn't afford to spend the time to finish
the work. "A clear vision" doesn't mean I can necessarily implement it in a
very small integral number of days.
In a sense, programming is all about what your program should do in the first
place. The how question is just the what , moved down the chain of
abstractions until it ends up where a computer can understand it, and at that
point, the three words multichannel audio support have become those 9,000
lines that describe in perfect detail what's going on.
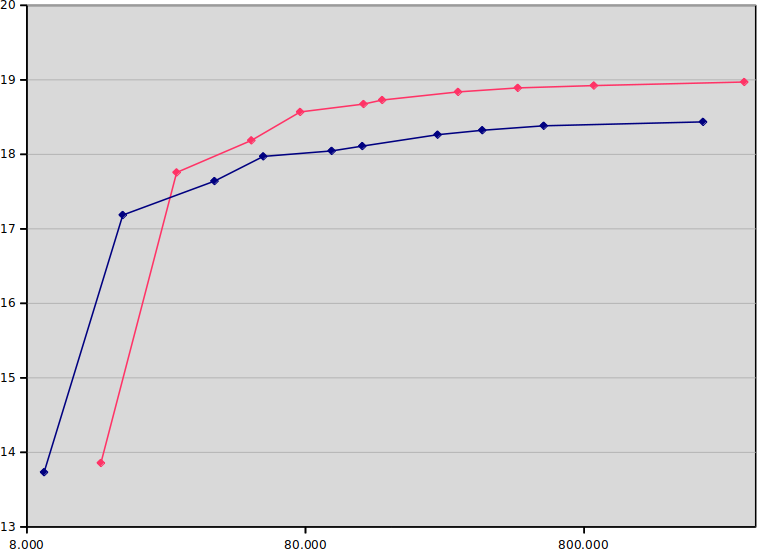 The x-axis is seconds used for the encode (note the logarithmic scale;
placebo takes 200 250 times as long as ultrafast).
The y-axis is SSIM dB, so up and to the left is better. The blue line is
8-bit, and the red line is 10-bit. (I ran most encodes five times and
averaged the results, but it doesn't really matter, due to the logarithmic
scale.)
The results are actually much stronger than I assumed; if you run on
(8-bit) ultrafast or superfast, you should stay with 8-bit, but from there
on, 10-bit is on the Pareto frontier. Actually, 10-bit veryfast (18.187 dB)
is better than 8-bit medium (18.111 dB), while being four times as fast!
But not all of us have a relation to dB quality, so I chose to also do a
test that maybe is a bit more intuitive, centered around bitrate needed for
constant quality. I locked quality to 18 dBm, ie., for each preset, I
adjusted the bitrate until the SSIM showed 18.000 dB plus/minus 0.001 dB.
(Note that this means faster presets get less of a speed advantage, because
they need higher bitrate, which means more time spent entropy coding.)
Then I measured the encoding time (again five times) and graphed the results:
The x-axis is seconds used for the encode (note the logarithmic scale;
placebo takes 200 250 times as long as ultrafast).
The y-axis is SSIM dB, so up and to the left is better. The blue line is
8-bit, and the red line is 10-bit. (I ran most encodes five times and
averaged the results, but it doesn't really matter, due to the logarithmic
scale.)
The results are actually much stronger than I assumed; if you run on
(8-bit) ultrafast or superfast, you should stay with 8-bit, but from there
on, 10-bit is on the Pareto frontier. Actually, 10-bit veryfast (18.187 dB)
is better than 8-bit medium (18.111 dB), while being four times as fast!
But not all of us have a relation to dB quality, so I chose to also do a
test that maybe is a bit more intuitive, centered around bitrate needed for
constant quality. I locked quality to 18 dBm, ie., for each preset, I
adjusted the bitrate until the SSIM showed 18.000 dB plus/minus 0.001 dB.
(Note that this means faster presets get less of a speed advantage, because
they need higher bitrate, which means more time spent entropy coding.)
Then I measured the encoding time (again five times) and graphed the results:
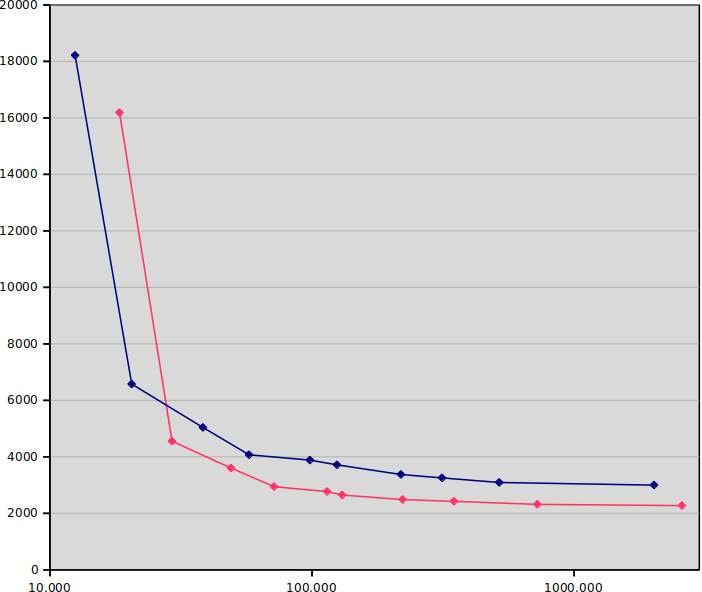 x-axis is again seconds, and y-axis is bitrate needed in kbit/sec, so lower
and to the left is better. Blue is again 8-bit and red is again 10-bit.
If the previous graph was enough to make me intrigued, this is enough to make
me excited. In general, 10-bit gives 20-30% lower bitrate for the same
quality and CPU usage! (Compare this with the supposed up to 50% benefits
of HEVC over H.264, given infinite CPU usage.) The most dramatic example
is when comparing the medium presets directly, where 10-bit runs at
2648 kbit/sec versus 3715 kbit/sec (29% lower bitrate!) and is only 5%
slower. As one progresses towards the slower presets, the gap is somewhat
narrowed (placebo is 27% slower and only 24% lower bitrate), but in the
realistic middle range, the difference is quite marked. If you run 3 Mbit/sec
at 10-bit, you get the quality of 4 Mbit/sec at 8-bit.
So is 10-bit H.264 a no-brainer? Unfortunately, no; the client hardware support
is nearly nil. Not even Skylake, which can do 10-bit HEVC encoding in
hardware (and 10-bit VP9 decoding), can do 10-bit H.264 decoding in hardware.
Worse still, mobile chipsets generally don't support it. There are rumors
that iPhone 6s supports it, but these are unconfirmed; some Android chips
support it, but most don't.
I guess this explains a lot of the limited uptake; since it's in some ways
a new codec, implementers are more keen to get the full benefits of HEVC instead
(even though the licensing situation is really icky). The only ones I know
that have really picked it up as a distribution format is the anime scene,
and they're feeling quite specific pains due to unique content (large
gradients giving pronounced banding in undithered 8-bit).
So, 10-bit H.264: It's awesome, but you can't have it. Sorry :-)
x-axis is again seconds, and y-axis is bitrate needed in kbit/sec, so lower
and to the left is better. Blue is again 8-bit and red is again 10-bit.
If the previous graph was enough to make me intrigued, this is enough to make
me excited. In general, 10-bit gives 20-30% lower bitrate for the same
quality and CPU usage! (Compare this with the supposed up to 50% benefits
of HEVC over H.264, given infinite CPU usage.) The most dramatic example
is when comparing the medium presets directly, where 10-bit runs at
2648 kbit/sec versus 3715 kbit/sec (29% lower bitrate!) and is only 5%
slower. As one progresses towards the slower presets, the gap is somewhat
narrowed (placebo is 27% slower and only 24% lower bitrate), but in the
realistic middle range, the difference is quite marked. If you run 3 Mbit/sec
at 10-bit, you get the quality of 4 Mbit/sec at 8-bit.
So is 10-bit H.264 a no-brainer? Unfortunately, no; the client hardware support
is nearly nil. Not even Skylake, which can do 10-bit HEVC encoding in
hardware (and 10-bit VP9 decoding), can do 10-bit H.264 decoding in hardware.
Worse still, mobile chipsets generally don't support it. There are rumors
that iPhone 6s supports it, but these are unconfirmed; some Android chips
support it, but most don't.
I guess this explains a lot of the limited uptake; since it's in some ways
a new codec, implementers are more keen to get the full benefits of HEVC instead
(even though the licensing situation is really icky). The only ones I know
that have really picked it up as a distribution format is the anime scene,
and they're feeling quite specific pains due to unique content (large
gradients giving pronounced banding in undithered 8-bit).
So, 10-bit H.264: It's awesome, but you can't have it. Sorry :-)
 Hooked it up to Nageru:
Hooked it up to Nageru:
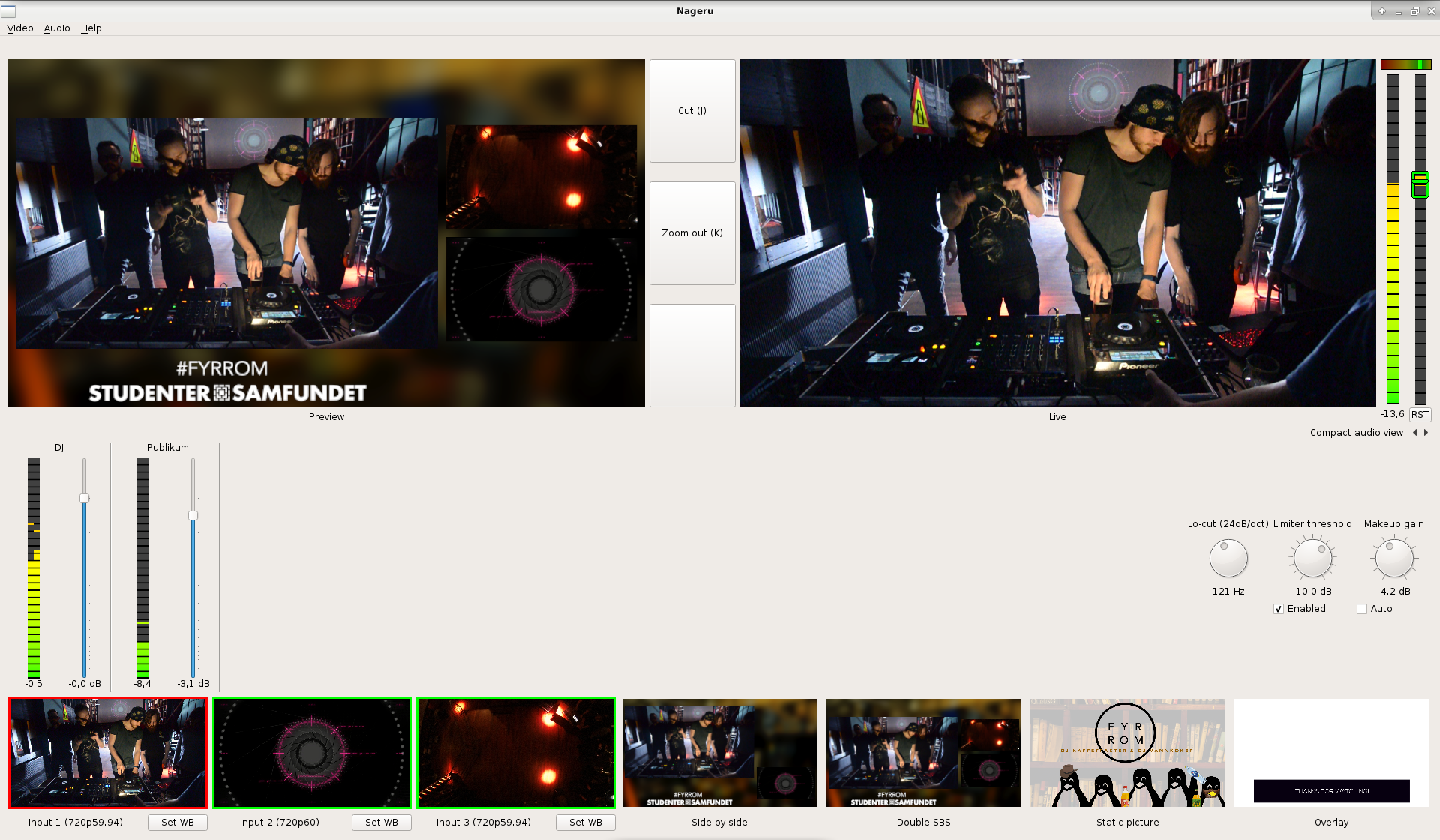
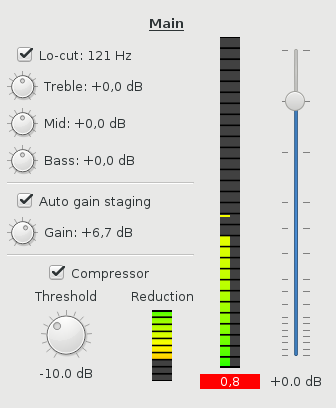 There's one set of these controls for each bus. (This is the expanded view; there's
also a compact view that has only the meters and the fader, which is what
you'll typically want to use during the run itself the expanded view is for
setup and tweaking.) A bus in Nageru is a pair of channels (left/right),
sourced from a video capture or ALSA card. The channel mapping is flexible;
my USB sound card has 18 channels, for instance, and you can use that to make
several buses. Each bus has a name (here I named it very creatively Main ,
but in a real setting you might want something like Blue microphone or
Speaker PC ), which is just for convenience; it doesn't mean much.
The most important parts of the mix are given the most screen estate,
so even though the way through the signal chain is left-to-right
top-to-bottom, I'll go over it in the opposite direction.
By far the most important part is the audio level, so the fader naturally is
very prominent. (Note that the scale is nonlinear; you want more resolution
in the most important area.) Changing a fader with the mouse or keyboard is
possible, and probably most people will be doing that, but Nageru will also
support USB faders. These usually speak MIDI, for historical reasons, and
there are some UI challenges when they're all so different, but you can get
really small ones if you want to get that tactile feel without blowing up
your budget or getting a bigger backpack.
Then there's the meter to the left of that. Nageru already has R128 level
meters in the mastering section (not shown here, but generally unchanged from
1.3.0), and those are kept as-is, but for each bus, you don't want to know loudness; you want to know
recording levels, so you want a peak meter, not a loudness meter. In particular, you don't want the bus to send clipped data
to the master (which would happen if you set it too high); Nageru can handle
this situation pretty well (unlike most digital mixers, it mixes in
full 32-bit floating-point so there's no internal clipping, and there's a limiter on the master by default),
but it's still not a good place to be in, so you can see that being marked
in red in this example. The meter doubles as an input peak check during
setup; if you turn off all the effects and set the fader to neutral, you can
see if the input hits peak or not, and then adjust it down. (Also, you can
see here that I only have audio in the left channel; I'd better check my
connections, or perhaps just use mono, by setting the right channel on the
bus mapping to the same input as the left one.)
The compressor (now moved from the mastering section to each bus) should be
well-known for those using 1.3.0, but in this view, it also has a reduction
meter, so that you can see whether it kicks in or not. Most casual users
would want to just leave the gain staging and compressor settings alone, but
a skilled audio engineer will know how to adjust these to each speaker's
antics (some speak at a pretty even volume and thus can get a bit of
headroom, while some are much more variable and need tighter settings).
Finally (or, well, first), there's the EQ section. The lo-cut is again
well-known from 1.3.0 (the cutoff frequency is the same across all buses),
but there's now also a simple three-band EQ per bus. Simply ask the speaker
to talk normally for a bit, and tweak the controls until it sounds good.
People have different voices and different ways of holding the microphone,
and if you have a reasonable ear, you can use the EQ to your advantage to
make them sound a little more even on the stream. Either that, or just
put it in neutral, and the entire EQ code will be bypassed.
The code is making pretty good progress; all the DSP stuff is done
(save for some optimizations I want to do in zita-resampler, now that
the discussion flow is started again),
and in theory, one could use it already as-is. However, there's a fair
amount of gnarly support code that still needs to be written: In particular,
I need to do some refactoring to support ALSA hotplug (you don't want
your entire stream to go down just because an USB soundcard dropped out
for a split second), and similarly some serialization of saving/loading
bus mappings. It's not exactly rocket science, but all the code still needs
to be written, and there are a number of corner cases to think of.
If you want to peek, the code is in the
There's one set of these controls for each bus. (This is the expanded view; there's
also a compact view that has only the meters and the fader, which is what
you'll typically want to use during the run itself the expanded view is for
setup and tweaking.) A bus in Nageru is a pair of channels (left/right),
sourced from a video capture or ALSA card. The channel mapping is flexible;
my USB sound card has 18 channels, for instance, and you can use that to make
several buses. Each bus has a name (here I named it very creatively Main ,
but in a real setting you might want something like Blue microphone or
Speaker PC ), which is just for convenience; it doesn't mean much.
The most important parts of the mix are given the most screen estate,
so even though the way through the signal chain is left-to-right
top-to-bottom, I'll go over it in the opposite direction.
By far the most important part is the audio level, so the fader naturally is
very prominent. (Note that the scale is nonlinear; you want more resolution
in the most important area.) Changing a fader with the mouse or keyboard is
possible, and probably most people will be doing that, but Nageru will also
support USB faders. These usually speak MIDI, for historical reasons, and
there are some UI challenges when they're all so different, but you can get
really small ones if you want to get that tactile feel without blowing up
your budget or getting a bigger backpack.
Then there's the meter to the left of that. Nageru already has R128 level
meters in the mastering section (not shown here, but generally unchanged from
1.3.0), and those are kept as-is, but for each bus, you don't want to know loudness; you want to know
recording levels, so you want a peak meter, not a loudness meter. In particular, you don't want the bus to send clipped data
to the master (which would happen if you set it too high); Nageru can handle
this situation pretty well (unlike most digital mixers, it mixes in
full 32-bit floating-point so there's no internal clipping, and there's a limiter on the master by default),
but it's still not a good place to be in, so you can see that being marked
in red in this example. The meter doubles as an input peak check during
setup; if you turn off all the effects and set the fader to neutral, you can
see if the input hits peak or not, and then adjust it down. (Also, you can
see here that I only have audio in the left channel; I'd better check my
connections, or perhaps just use mono, by setting the right channel on the
bus mapping to the same input as the left one.)
The compressor (now moved from the mastering section to each bus) should be
well-known for those using 1.3.0, but in this view, it also has a reduction
meter, so that you can see whether it kicks in or not. Most casual users
would want to just leave the gain staging and compressor settings alone, but
a skilled audio engineer will know how to adjust these to each speaker's
antics (some speak at a pretty even volume and thus can get a bit of
headroom, while some are much more variable and need tighter settings).
Finally (or, well, first), there's the EQ section. The lo-cut is again
well-known from 1.3.0 (the cutoff frequency is the same across all buses),
but there's now also a simple three-band EQ per bus. Simply ask the speaker
to talk normally for a bit, and tweak the controls until it sounds good.
People have different voices and different ways of holding the microphone,
and if you have a reasonable ear, you can use the EQ to your advantage to
make them sound a little more even on the stream. Either that, or just
put it in neutral, and the entire EQ code will be bypassed.
The code is making pretty good progress; all the DSP stuff is done
(save for some optimizations I want to do in zita-resampler, now that
the discussion flow is started again),
and in theory, one could use it already as-is. However, there's a fair
amount of gnarly support code that still needs to be written: In particular,
I need to do some refactoring to support ALSA hotplug (you don't want
your entire stream to go down just because an USB soundcard dropped out
for a split second), and similarly some serialization of saving/loading
bus mappings. It's not exactly rocket science, but all the code still needs
to be written, and there are a number of corner cases to think of.
If you want to peek, the code is in the
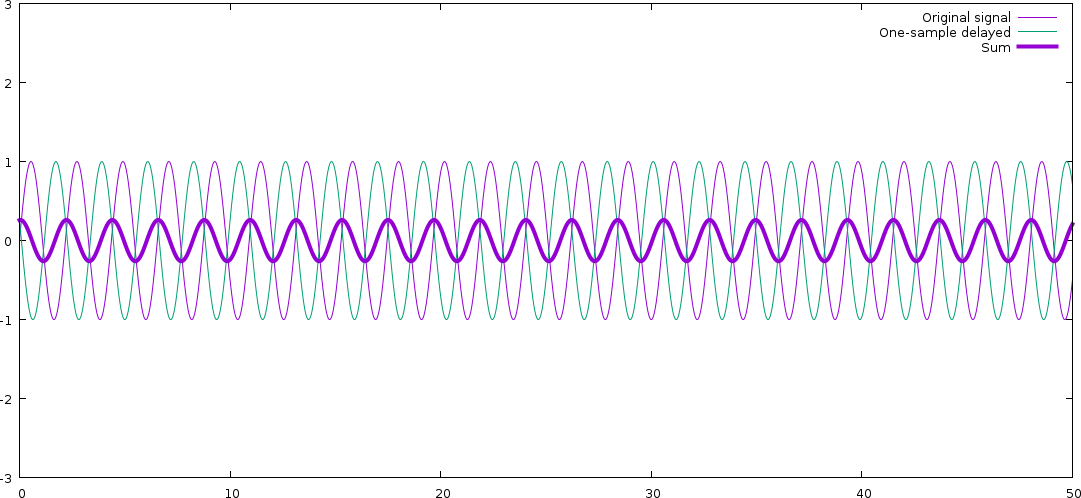 As you can see, the resulting signal is a new signal of the same frequency
(which is always true; linear filtering can never create new frequencies,
just boost or dampen existing ones), but with much lower amplitude.
The signal and the delayed version of it end up cancelling each other mostly
out. Also note that there signal has changed phase; the resulting signal
has been a bit delayed compared to the original.
Now let's look at a 50 Hz signal (turn on your bass face). We need to zoom out a bit to see
full 50 Hz cycles:
As you can see, the resulting signal is a new signal of the same frequency
(which is always true; linear filtering can never create new frequencies,
just boost or dampen existing ones), but with much lower amplitude.
The signal and the delayed version of it end up cancelling each other mostly
out. Also note that there signal has changed phase; the resulting signal
has been a bit delayed compared to the original.
Now let's look at a 50 Hz signal (turn on your bass face). We need to zoom out a bit to see
full 50 Hz cycles:
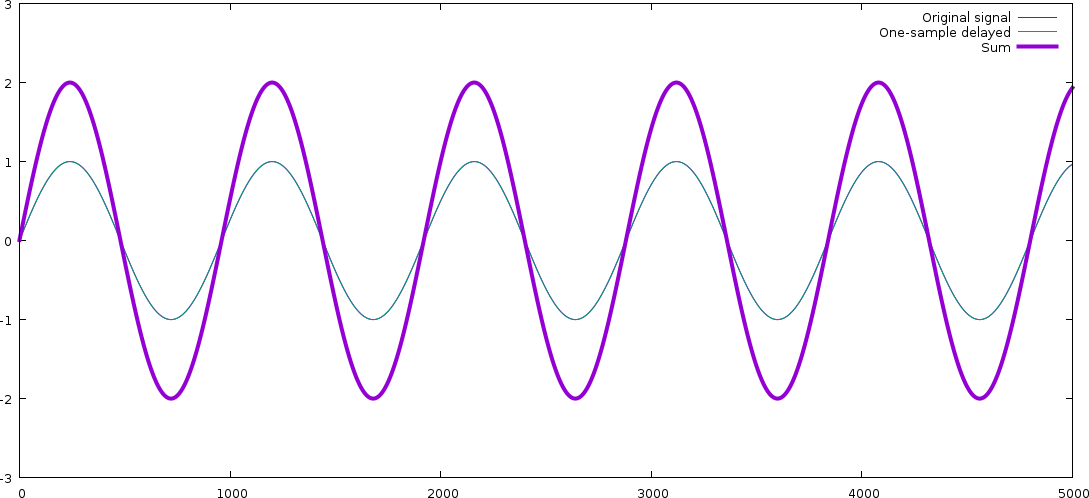 The original signal and the delayed one overlap almost exactly! For a lower
frequency, the one-sample delay means almost nothing (since the waveform is
varying so slowly), and thus, in this case, the resulting signal is amplified,
not dampened. (The signal has changed phase here, too actually exactly as much
in terms of real time but we don't really see it, because we've zoomed out.)
Real signals are not pure sines, but they can be seen as sums of many sines
(another fundamental DSP result), and since filtering is a linear operation,
it affects those sines independently. In other words, we now have a very
simple filter that will amplify low frequencies and dampen high frequencies
(and delay the entire signal a little bit). We can do this for all
frequencies from 0 to 24000 Hz; let's ask Octave to do it for us:
The original signal and the delayed one overlap almost exactly! For a lower
frequency, the one-sample delay means almost nothing (since the waveform is
varying so slowly), and thus, in this case, the resulting signal is amplified,
not dampened. (The signal has changed phase here, too actually exactly as much
in terms of real time but we don't really see it, because we've zoomed out.)
Real signals are not pure sines, but they can be seen as sums of many sines
(another fundamental DSP result), and since filtering is a linear operation,
it affects those sines independently. In other words, we now have a very
simple filter that will amplify low frequencies and dampen high frequencies
(and delay the entire signal a little bit). We can do this for all
frequencies from 0 to 24000 Hz; let's ask Octave to do it for us:
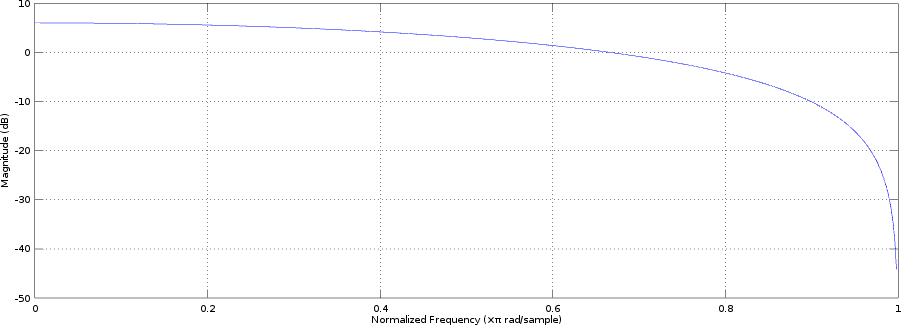 (Of course, in a real filter, we'd probably multiply the result with 0.5
to leave the bass untouched instead of boosting it, but it doesn't really
change anything. A real filter would have a lot more coefficients, though,
and they wouldn't all be the same!)
Let's now turn to a problem that will at first seem different: Combining
audio from multiple different time sources. For instance, when mixing video,
you could have input from two different cameras or sounds card and would want
to combine them (say, a source playing music and then some audience sound
from a camera). However, unless you are lucky enough to have a professional-grade setup
where everything runs off the same clock (and separate clock source cables
run to every device), they won't be in sync; sample clocks are good, but they are
not perfect, and they have e.g. some temperature variance. Say we have really
good clocks and they only differ by 0.01%; this means that after an hour of
streaming, we have 360 ms delay, completely ruining lip sync!
This means we'll need to resample at least one of the sources to match the
other; that is, play one of them faster or slower than it came in originally.
There are two problems here: How do you determine how much to resample
the signals, and how do we resample them?
The former is a difficult problem in its own right; about every algorithm
not backed in solid control theory
is doomed to fail in one way or another, and when they fail, it's extremely
annoying to listen to. Nageru follows
(Of course, in a real filter, we'd probably multiply the result with 0.5
to leave the bass untouched instead of boosting it, but it doesn't really
change anything. A real filter would have a lot more coefficients, though,
and they wouldn't all be the same!)
Let's now turn to a problem that will at first seem different: Combining
audio from multiple different time sources. For instance, when mixing video,
you could have input from two different cameras or sounds card and would want
to combine them (say, a source playing music and then some audience sound
from a camera). However, unless you are lucky enough to have a professional-grade setup
where everything runs off the same clock (and separate clock source cables
run to every device), they won't be in sync; sample clocks are good, but they are
not perfect, and they have e.g. some temperature variance. Say we have really
good clocks and they only differ by 0.01%; this means that after an hour of
streaming, we have 360 ms delay, completely ruining lip sync!
This means we'll need to resample at least one of the sources to match the
other; that is, play one of them faster or slower than it came in originally.
There are two problems here: How do you determine how much to resample
the signals, and how do we resample them?
The former is a difficult problem in its own right; about every algorithm
not backed in solid control theory
is doomed to fail in one way or another, and when they fail, it's extremely
annoying to listen to. Nageru follows {kind=link}